3D 目标检测之鸟瞰图检测 (Pixor / HDNet)
随着无人驾驶的兴起,激光雷达数据的目标检测成为了这几年的研究热点之一。常见的 3D 检测模型可以分成两类,一类是用 3D 小方格代表所有的激光点数据,每个小方格包含了这个方格内的特征,例如 VoxelNet 和 Vote3deep 。另一类则是先把三维信息投射到一个二维平面,通常是鸟瞰图 (BEV, Bird Eye View) 或是正视图 (Range View),生成二维特征图后再用传统的二维目标模型检测图中的物体,例如 MV3D 和 FaF。
无人驾驶场景中的大多数的目标物体都处在同一地面上,非常适合 BEV。相比正视图,BEV 中的目标在不同位置大小固定,我们可以用已知的常见物体大小优化检测效果。对于 BEV 模型来说,主要的问题在于如何选择最终图像的特征,如何生成的图像中做出精确的检测。此文旨在介绍 BEV 检测相关的模型 Pixor 和 HDNet。
Pixor
Pixor 是 Uber ATG 的 Bin Yang 等人在 CVPR 18 上提出的 BEV 检测模型。在特征生成方面,Pixor 把整个点云切成了 L x W x H 个小方格,每个小方格用 0 或 1 表示这个方格内是否有激光点存在,接着沿高度方向把三维特征压缩到一个二维平面,每个压缩后的二维方格就有了 H 个特征表示这个方格上的不同高度是否有点存在。此外 Pixor 还计算了落在每个方格中激光点的平均强度作为额外的特征,最终拿到了一个分辨率为 L x W、包含 H + 1 个特征通道的图像。
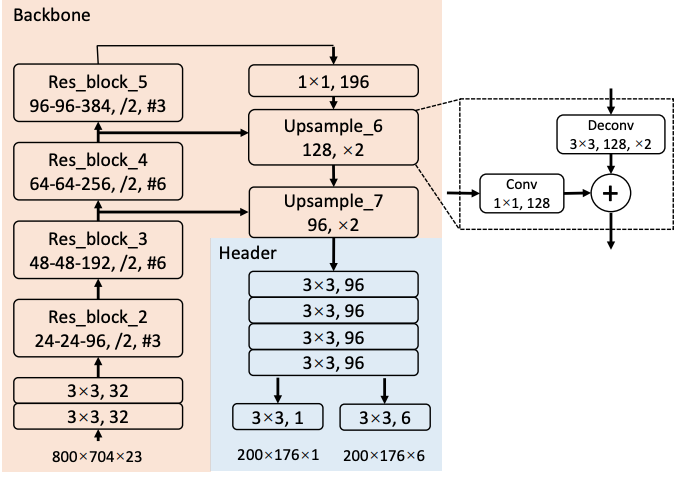
检测方面,Pixor 采用了基于 RetinaNet 的 one-stage 的结构,如上图所示(这里用了海报上的截图,和论文中的有一些细小的差别)。网络里面用了 ResNet 和类似 FPN 的结构。FPN 结构输出的特征图经过一个头部网络后,直接生成对每个像素点的分类和 bounding box 的回归结果。
优化目标方面,分类目标用了 RetinaNet 中的 focal loss,回归目标用了 smoooth L1。论文中回归目标有笔误,按照海报和 FAQ 的说法应该是 \(\{ \cos 2\theta, \sin 2\theta, dx, dy, \log W, \log L \}\)。这里巧妙的用了 \(2 \theta\) 的三角函数作为车头朝向的回归目标,因为车辆是往前还是往后开这个问题会在 tracker 中处理,在检测的时候只要知道车身线的偏离角度就行了,至于这个角度是 5° 还是 185° 影响不大。
整个网络的运行速度非常快,在 Titan XP 上可以在 35 毫秒内完成。除此之外论文还测试了不同 backbone 网络和头部网络特征层共享的不同选择,做了模型简化测试 (ablation study),感兴趣的朋友可以细读。
HDNet
Pixor 沿高度方向把整个点云切成不同的高度区间,例如 Kitti 数据集上 -2.5 到 1 米之间的点会被分成 35 片,这个区间之外的点会被忽略。当地面坡度较大时,远处的点很容易被排除在外。为了解决这个问题,Bin Yang 等人提出了把高精地图作为额外特征的方案,发表在 CoRL 18 上。

如图所示,HDNet 的核心思路在于引入了高精地图信息,从而可以把地面「摊平」(图 b),并提供道路语义信息帮助检测(图 d)。网络结构和 Pixor 非常相似,采用了 FPN,并把 Pixor 中的反卷积层换成了更高效的双线性插值层。
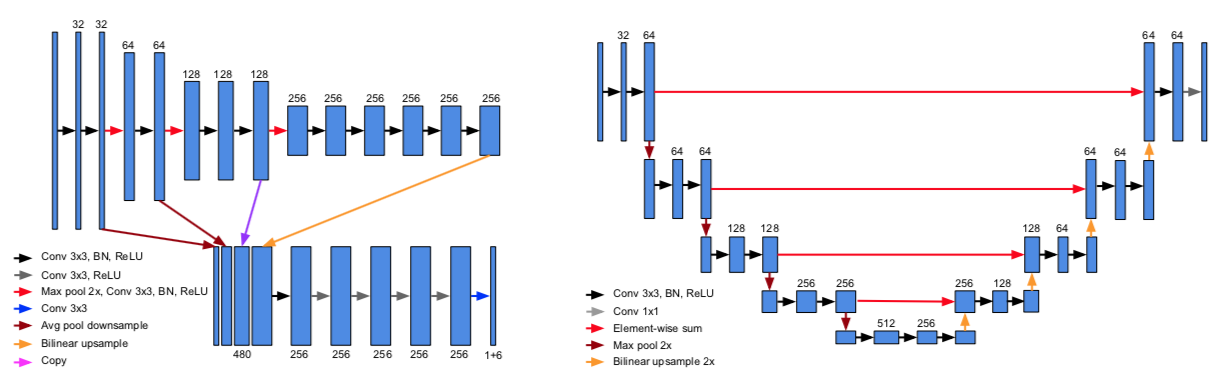
为了提高模型的稳定性,确保在缺失地图信息或者地图不准确的情况下仍然有较好的检测结果,作者会在训练模型时随机去除地图信息,并提出了通过 Lidar 扫描结果在线生成地图的方案。
小结
本文介绍了两篇近期的基于纯激光雷达数据的 BEV 检测论文。基于纯激光雷达的模型非常适合车辆的检测,但对于行人检测的精度并不理想,往往需要借助图像提供额外的信息。在接下来的博客中我会和大家一起分享更多的相关研究,同时也欢迎各位提出不同的意见。
最后做一个小广告,我目前在 Ike 做无人卡车视觉的相关工作。我们公司在旧金山,最近拿到了 5200 万 A 轮融资,正在招人中。如果你对无人卡车感兴趣,欢迎联系我。