SLAM 公开课笔记 2:卡尔曼滤波
这一周主要讲卡尔曼滤波 (Kalman Filter),视频讲得比较简略,slides 做得里也有不少错误。最后看了一些其他网站的文章和视频才有了比较深刻的理解。参考资料推荐在本文结尾。
卡尔曼滤波 KF
卡尔曼滤波可以从一系列包含噪音的观测数据中,估计出每个时间点系统的状态。KF 有几个基本假设:
- 当前状态只和前一状态有关,且和前一状态线性相关,即 \(x_{t+1}=A_t x_{t} + B_t u_t + \epsilon_t\),这里 \(x_t\) 是状态向量,\(u_t\) 为控制向量,\(\epsilon_t\) 是均值为 0 的高斯分布噪音。
- 测量结果和状态线性相关:\(z_t = C_t x_t + \delta_t\)。这里 \(z_t\) 是测量结果的向量,\(\delta_t\) 表示测量噪音。
- 最初状态也呈正态分布。
基于高斯分布的假设,我们可以用贝叶斯模型描述状态 \[ p(x_{t+1}|x_t) = Ap(x_t) \\ p(z_t|x_t) = Cp(x_t) \]
加入运动和观测误差导致的不确定性 \(v_m\) 和 \(v_0\) \[ p(x_{t+1}|x_t) = Ap(x_t)+v_m \\ p(z_t|x_t) = Cp(x_t)+v_0 \]
假设误差基于高斯分布 \[ p(x_{t+1}|x_t) = A\mathcal{N}(x_t, P_t) + \mathcal{N}(0, \Sigma_m) \\ p(z_t|x_t) = C\mathcal{N}(x_t, P_t) + \mathcal{N}(0, \Sigma_0) \]
把线性变换 A 和 C 代入正态分布 \[ p(x_{t+1}|x_t) = \mathcal{N}(Ax_t, A P_t A^T) + \mathcal{N}(0, \Sigma_m) \\ p(z_t|x_t) = \mathcal{N}(Cx_t, C P_t C^T) + \mathcal{N}(0, \Sigma_0) \]
线性加和 \[ p(x_{t+1}|x_t) = \mathcal{N}(Ax_t, A P_t A^T+ \Sigma_m) \\ p(z_t|x_t) = \mathcal{N}(Cx_t, C P_t C^T + \Sigma_0) \]
接下来讲如何估计这两个高斯分布的参数。
最大后验概率估计卡尔曼滤波
最大后验概率估计的目的在于最大化后验概率 \(p(x_t | z_t)\),即在对 \(x_t\) 有一个预测(先验),同时获得了观测结果 \(z_t\) 之后修正 \(x_t\) 的值,用符号表示有 \(\hat{x_t} = \argmax_{x_t} p(x_t | z_t)\)
由贝叶斯公式 \[ p(x_t | z_t) = \frac{p(z_t | x_t) p(x_t)}{P (z_t)} \] 代入正态分布得 \[ \hat{x_t} = \argmax_{x_t} \mathcal{N}(Cx_t, \Sigma_0) \mathcal{N}(Ax_t, A P_t A^T+ \Sigma_m) \] 令 \[ \begin{align} P &= A P_{t-1} A^T + \Sigma_m \\ R &= \Sigma_0 \end{align} \] 代入多元高斯分布(参考第一周笔记)把两个分布合并后求导,或者利用边界条件概率公式,可解得 \[ \begin{align} \hat{x_t} &= (P^{-1} + C^T R^{-1}C)^{-1} (C^T R^{-1} Z_t + P^{-1} A x_{t-1}) \\ \hat{P_t} &= (P^{-1} + C^T R^{-1}C)^{-1} \end{align} \]
接下来根据 Woodbury 矩阵求逆式 (Woodbury Matrix Identity),可以得到 \[ \hat{P_t} = P - P C^T (R^{-1} + C P C^T)^{-1} C P \] 令 \(K = P C^T (R + C P C^T)^{-1}\),有 \(\hat{P_t} = P - KCP\),\(\hat{x_t}\) 简化过程如下 \[ \begin{align} \hat{x_t} &= (P^{-1} + C^T R^{-1}C)^{-1} (C^T R^{-1} z_t + P^{-1} A x_{t-1}) \\ &= (P - KCP) (C^T R^{-1} z_t + P^{-1} A x_{t-1}) \\ &= A x_{t-1} + P C^T R^{-1} z_t - K C A x_{t-1} - KCP C^T R^{-1} z_t \\ &= A x_{t-1} - K C A x_{t-1} + (P C^T R^{-1} - KCP C^T R^{-1}) z_t \\ &= A x_{t-1} - K C A x_{t-1} + K z_t \end{align} \]
这里 K 就是卡尔曼增益 (Kalman gain)。
扩展卡尔曼滤波 (Extended Kalman Filter)
KF 的局限之一在于假设了线性模型,EKF 去掉了线性模型的限制,可以处理更一般的状态变化函数 \[ \begin{align} x_{t+1} = A x_t + B u_t &=> x_{t+1} = f(x_t, u_k) \\ z_t = C x_t &=> z_t = h(x_t) \end{align} \]
于是协方差的预测变成了 \[ p(x_{t+1}|x_t) = \mathcal{N}(f(x_t), \frac{\partial{f}}{\partial{x}} P_t \frac{\partial{f^T}}{\partial{x}} + \Sigma_m) \] 卡尔曼增益为 \[ K = P \frac{\partial{h^T}}{\partial{x}} (\frac{\partial{h}}{\partial{x}} P_t \frac{\partial{h^T}}{\partial{x}})^{-1} \] 更新方程为 \[ \begin{align} \hat{x_t} &= f(x_{t-1}) + K(z_t - h(f(x_t))) \\ \hat{P_t} &= P - K \frac{\partial{h}}{\partial{x}} P \end{align} \]
无迹卡尔曼滤波 (Unscented Kalman Filter)
EKF 的局限之一在于只是对非线性的变换做了近似,用泰勒级数展开后取一阶项,容易产生导致较大的误差。UKF 采用了确定性的取样方法来近似高斯分布,这个取样方法又被称为无迹变换 (Unscented Transformation)。
Unscented Transformation
UT 可以用来计算非线形变换后随机变量的分布情况。考虑 L 维随机变量 x 和非线性的函数 \(\pmb{y} = f(\pmb{x})\),假设 x 的均值为 \(\bar{\pmb{x}}\),协方差矩阵 \(P_x\)。为了计算 \(\pmb{y}\) 的分布情况,我们根据下面三个式子创造一个维数为 2L + 1 的 sigma 矩阵 \(\pmb{\mathcal{X}}\): \[ \begin{align} \mathcal{X}_0 &= \bar{\pmb{x}} \\ \mathcal{X}_i &= \bar{\pmb{x}} + (\sqrt{(L + \lambda)\pmb{P}_x})_i && i = 1, \dots, L \\ \mathcal{X}_i &= \bar{\pmb{x}} + (\sqrt{(L + \lambda)\pmb{P}_x})_{i - L} && i = L + 1, \dots, 2L \end{align} \] 这里 \(\lambda = \alpha^2(L + \kappa) - L\) 为调节参数,\(\alpha\) 决定采样点围绕均值的扩散程度等参数。下标 i 表示矩阵的第 i 列。这里的 \(\mathcal{X}_i\) 也被称为 sigma 向量,通过非线性函数后转变到同一个矩阵中: \[ \mathcal{Y}_i = f(\mathcal{X}_i) \]
\(\pmb{y}\) 的均值和协方差就可以通过对 \(\mathcal{Y}\) 矩阵列的加权求和获得了 \[ \begin{align} \pmb{y} &\approx \sum_{i=0}^{2L} W_i^{(m)} \mathcal{Y}_i \\ \pmb{P}_y &\approx \sum_{i=0}^{2L} W_i^{(c)} \{\mathcal{Y}_i - \bar{\pmb{y}}\}\{\mathcal{Y}_i - \bar{\pmb{y}}\}^T \end{align} \] 其中权值 \(W_i\) 的定义为 \[ \begin{align} W_0^{(m)} &= \lambda / (L + \lambda) \\ W_0^{(c)} &= \lambda / (L + \lambda) + (1 - \alpha^2 + \beta) \\ W_0^{(c)} &= W_0^{(m)} = 1 / \{ 2(L + \lambda) \} & i = 1, \dots, 2L. \end{align} \] 下图很好地解释了上述几个式子的变换过程
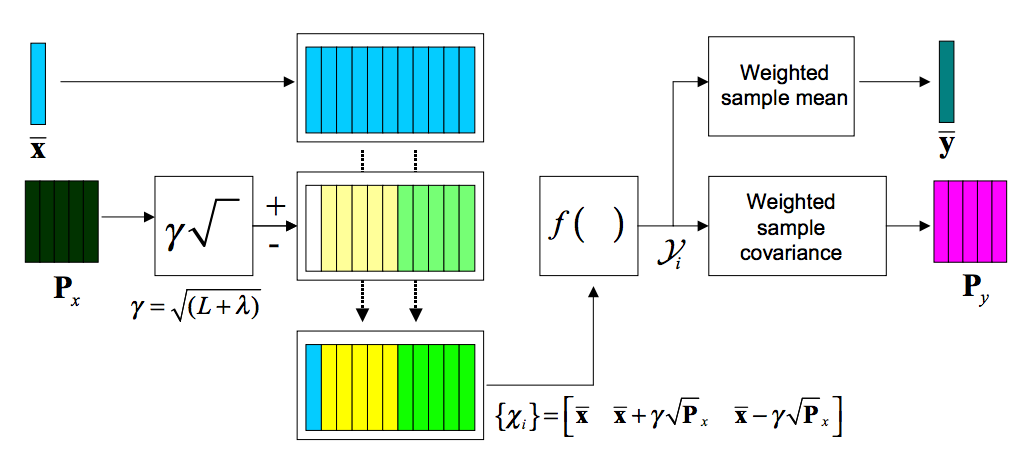
Unscented Kalman Filter
接下来回到 UKF。介绍了 UT 之后 UKF 就容易多了。首先构造一个包含初始状态和噪音的矩阵 \(\pmb{x}_k^{\alpha} = [\pmb{x}_k^T \pmb{v}_k^T \pmb{n}_k^T ]^T\),这里三个向量分别为状态向量、控制向量和噪音向量。接下来对这个矩阵应用无迹变换获得 sigma 矩阵 \(\mathcal{X}_k^{\alpha}\),之后就回到了普通 KF 过程。具体的状态转移公式可以参考本文结尾参考资料《Kalman Filtering and Neural Networks》一书中的章节。
作业
这周的作业是用卡尔曼滤波预测一个小球运动 10 帧之后的位置。理解了卡尔曼滤波后做起来不难,定义好动力学矩阵 A 和测量矩阵 C,接着根据上面的公式计算卡尔曼增益 K、新状态的均值和协方差矩阵,再通过新状态的位置和速度计算 10 帧之后的位置就好。
调参方面有一些小技巧,一开始测试的时候可以先给 \(\Sigma_m\) 设一个很大的值,同时给 \(\Sigma_0\) 设一个很小的值,这样每次算出来的位置都应该是测量出来的位置,否则代码里可能有 bug。接下来就可以根据生成的预测图来调整 \(\Sigma_m\),肉眼估一下坐标的误差范围(注意到 y 的变化速度比 x 的慢很多),然后根据坐标误差算一下速度误差。测量误差根据文档可以给一个 0.01 - 0.1 的参数。
参考资料
- How a Kalman filter works, in pictures:这篇是最推荐的,作者还用不同颜色标记各个变量,看起来一目了然。
- Kalman Filter 学习笔记:上文的中文版。
- 《Probabilistic Robotics》一书第三章,pdf 版可以在这里下到。
- Michel van Biezen 的 Kalman Filter 视频:https://youtu.be/CaCcOwJPytQ 比较长,一共有 55 集,但是讲得很细致。
- The Extended Kalman Filter: An Interactive Tutorial for Non-Experts:EKF 的介绍网站,只要求高中数学基础。
- The Unscented Kalman Filter for Nonlinear Estimation: UKF 论文。
- 《Kalman Filtering and Neural Networks》第七章:EKF 和 UKF 的详细介绍。
全课程的笔记链接
- Robotics Estimation and Learning 的课程主页
- 第一周笔记:高斯分布
- 第二周笔记:卡尔曼滤波
- 第三周笔记:地图
- 第四周笔记:定位